- Published on
【译】可编程的web项目(二)
- Authors
- Name
- Zifan Xiao


API 设计
写在开头: 本译文源自芬兰奥卢大学 Ivan Sanchez 的课程 Programmable web project,由三位在奥卢大学交换生分享译制,如有措辞不当或任何不妥,请前辈们多多在评论中指点。原课程programmable-web-project。课程中的练习原本有上传自动检验,但需要学校账号选课登陆,在此直接分享答案。
任何转载、再翻译等共享方式需遵循 CC-BY-SA 4.0 协议。
在本章练习中你将学会如何设计自己的超媒体接口,同时学会如何利用Apiary来创建专业的接口文档。
在实现自己的接口前完成一份专业的 API 文档十分重要。第一,实现接口前你需要考虑到客户端访问 API 的最佳方式,从而得出最好的设计方案,如果没有提前写好的设计文档,直接完成的 API 的就会过分基于接口实现的代码,从而会有一定的局限性。第二,在设计文档的过程中你需要考虑到 API 的返回情况,即能在实现接口前接收到 API 的反馈,与修改已实现的 API 相比,对设计和文档的更正会容易很多。
API 概念
本章练习中的 API 是一个基于音乐元数据存储的服务接口,主要可以用来管理与完善和音乐有关的数据。在这个例子当中,数据结构并不是很复杂:音乐元数据总共分为三个模块:艺术家(artist),专辑(album)和播放记录(track);艺术家是专辑的作者,每个专辑会有一个播放记录。拥有一个清晰的结构后就很容易去创建数据库。
难点一
在这个例子中,第一个难点是艺术家或专辑的重名问题,记录重名的艺术家和专辑是一件很棘手的事情;其次对于同一张专辑来说,可能会出现多个‘未命名’的播放记录。所以说,在设计 API 之前,需要找到一个方法或者调用其他接口来解决‘不唯一’这个难题。
难点二
第二个难点是‘群星’(various artists)问题,简称 VA。由于会存在多个艺术家合作的情况,同一张专辑就会有多个艺术家,所以在这种情况下,对这张专辑的播放记录就需要根据不同艺术家来分开处理。
相关服务
为了更好地理解本例中的 API,我们在此提供几个相似的基于音乐数据的服务:Musicbrainz, FreeDB. 此外,我们提供一个可以用到本例中 API 的数据源:last.fm
数据库设计
根据上面所提到的概念,我们可以创建一个拥有三个模型(models)的数据库:album,artist 和 track. 同时,我们在创建数据库的时候还需要考虑到‘群星’的情况,即还有两个需要特别注意的存在:拥有多个艺术家的专辑(VA album)和基于多个艺术家的播放记录(VA track)。在创建数据库的过程中,我们要考虑到每个模块的‘唯一性约束’;同时在此提醒,在创建模块时,我们应该避免使用原始数据库 ID 来定位 API 中的资源,第一是因为原始 ID 并不具有任何意义,第二是因为这样会给一些不希望未经授权用户推断出有关信息的 API 带来漏洞。
‘唯一性约束’允许我们定义更复杂的唯一性,而不仅仅是将单个列定义为唯一。如果想定义模块中的多个列为唯一,即这些列中的特定值组合只能出现一次,我们可以将多个列设进‘唯一性约束’中。例如,我们可以假设同一个艺术家不会有两个相同名字的专辑(不考虑多次编辑的情况),但是不同艺术家的专辑可能有相同的名字,因此我们并不能将单张专辑的标题定为唯一,而是应该将专辑标题与艺术家 ID 的组合定为唯一,所以此时我们可以将这两列一起设进‘唯一性约束’中。
def Album(db.Model):
__table_args__ = (db.UniqueConstraint("title", "artist_id", name="_artist_title_uc"), )
注意上述代码中最后的逗号:这是告诉 Python 这是一个元组而不是一个正常插入的普通值。你可以在‘唯一性约束’中的元组参数中加上任何想加的列。上述代码中的‘name’是必须存在的,所以请尽量让它具有表达意义。对单个播放记录来说,我们应该给它一个更完善的‘唯一性约束’:对一张专辑来说,每个播放记录都应该有一个单独的索引号,所以对播放记录来说,‘唯一性约束’应该是专辑 ID,播放记录数量和播放记录索引号的组合。
def Track(db.Model):
__table_args__ = (db.UniqueConstraint("disc_number", "track_number", "album_id", name="_track_index_uc"), )
为了解决‘群星’问题,我们将允许 album 模块中的外键‘artist’为空,并且加一个可选字段‘va_artist’。最终的数据库代码如下:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.engine import Engine
from sqlalchemy import event
from sqlalchemy.exc import IntegrityError, OperationalError
app = Flask(__name__, static_folder="static")
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///development.db"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db = SQLAlchemy(app)
@event.listens_for(Engine, "connect")
def set_sqlite_pragma(dbapi_connection, connection_record):
cursor = dbapi_connection.cursor()
cursor.execute("PRAGMA foreign_keys=ON")
cursor.close()
va_artist_table = db.Table("va_artists",
db.Column("album_id", db.Integer, db.ForeignKey("album.id"), primary_key=True),
db.Column("artist_id", db.Integer, db.ForeignKey("artist.id"), primary_key=True)
)
class Track(db.Model):
__table_args__ = (db.UniqueConstraint("disc_number", "track_number", "album_id", name="_track_index_uc"), )
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String, nullable=False)
disc_number = db.Column(db.Integer, default=1)
track_number = db.Column(db.Integer, nullable=False)
length = db.Column(db.Time, nullable=False)
album_id = db.Column(db.ForeignKey("album.id", ondelete="CASCADE"), nullable=False)
va_artist_id = db.Column(db.ForeignKey("artist.id", ondelete="SET NULL"), nullable=True)
album = db.relationship("Album", back_populates="tracks")
va_artist = db.relationship("Artist")
def __repr__(self):
return "{} <{}> on {}".format(self.title, self.id, self.album.title)
class Album(db.Model):
__table_args__ = (db.UniqueConstraint("title", "artist_id", name="_artist_title_uc"), )
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String, nullable=False)
release = db.Column(db.Date, nullable=False)
artist_id = db.Column(db.ForeignKey("artist.id", ondelete="CASCADE"), nullable=True)
genre = db.Column(db.String, nullable=True)
discs = db.Column(db.Integer, default=1)
artist = db.relationship("Artist", back_populates="albums")
va_artists = db.relationship("Artist", secondary=va_artist_table)
tracks = db.relationship("Track",
cascade="all,delete",
back_populates="album",
order_by=(Track.disc_number, Track.track_number)
)
sortfields = ["artist", "release", "title"]
def __repr__(self):
return "{} <{}>".format(self.title, self.id)
class Artist(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String, nullable=False)
unique_name = db.Column(db.String, nullable=False, unique=True)
formed = db.Column(db.Date, nullable=True)
disbanded = db.Column(db.Date, nullable=True)
location = db.Column(db.String, nullable=False)
albums = db.relationship("Album", cascade="all,delete", back_populates="artist")
va_albums = db.relationship("Album",
secondary=va_artist_table,
back_populates="va_artists",
order_by=Album.release
)
def __repr__(self):
return "{} <{}>".format(self.name, self.id)
资源设计
在定义完数据库模块后,我们可以开始考虑设计资源。在 RESTful API 中,资源可以是任何一个客户想要获取的东西。现在我们需要根据上面定义的三个数据库模块来定义我们的资源。之后,我们还将解释在这个 API 例子中,该如何基于 RESTful 规则使用 HTTP 方法来对我们的资源进行操作。
数据库模块中的资源
一个资源,应该是一个对客户有足够吸引力,值得我们为其定义一个 URI(统一资源标识符)的数据,同样地,每个资源都应该通过自己的 URI 被定义为唯一资源。对一个 API 来说,资源的数量有数据库表数量的两倍之多是一件很正常的事情,第一是因为对每个数据库表来说,客户可能会想要获取整个表作为一个‘集合’数据,也可能会想要单独访问表中某一行来获取‘个体’数据。有时候,即使‘集合’数据中已经包含了所有‘个体’数据,但是为了能让客户操纵数据,我们仍需要将‘个体’数据设置为一个单独的资源。
根据上面的这个解释,我们可以暂时定义 6 个资源:
- artist collection
- artist item
- album collection
- album item
- track collection
- track item
值得注意的是,一个‘集合’类资源并不是一定要包含相关表中的所有内容。举例说明,对在整个数据层次中处于最高层的艺术家而言,拥有一个包含所有艺术家的集合是一个有意义的操作; 但像 track 表中包含了所有有关播放记录的数据,这所有的播放记录放在一起作为一个集合的意义并不大,我们需要的更有意义的集合,例如根据不同专辑分组的播放记录集合。 对专辑来说,和播放记录的处理方式一样,将根据不同艺术家分组的专辑合集定为资源更有意义(一个特定艺术家的所有专辑)。同时,我们还需要考虑到‘群星’问题,那么我们可以定义两个不同的‘集合’资源:一个是某个特定艺术家的所有专辑,另一个是多个艺术家的所有专辑。 最终我们将资源定义为:
- artist collection
- artist item
- albums by artist collection
- VA albums collection
- album item(incorporates track collection)
- track item
与普通专辑相比,我们对 VA 专辑的处理方式略有不同。为了更好地记录 VA 专辑的播放数据,我们需要再加一些单独的数据表达作为资源。最后我们也可以加上所有专辑的集体资源,这是为了让客户可以看到我们的 API 提供了哪些专辑数据。
- artist collection
- artist item
- all albums collection
- albums by artist collection
- VA albums collection
- album item(incorporates track collection)
- track item
- VA track item
定位资源
在定义完资源后,并且分析出资源重要性排名后,我们需要给每个资源定义一个 URI,使每个资源是被唯一定义的(addressability principle)。 我们需要定义 URI 层次结构,我们希望通过 URIs 来传达资源之间的联系。对于普通专辑来说,资源层次结构如下:
artist collection
└── artist
└── album collection
└── album
└── track
我们设定专辑标题加上艺术家 ID 是唯一的,同时,识别一个唯一的播放记录的最好方式就是将其索引号和播放名称与一张具体的专辑结合起来作为识别符。 将上面所有的因素考虑进去,我们最终可以得到一个路径:
/api/artists/{'{artist_unique_name}'}/albums/{album_title}/{disc}/{track}/
上面这个路径可以唯一地定义每一个播放记录,并且将数据层次清晰地表达了出来,所有在层次结构中的资源(包括集合和个体),都可以通过从上面这个路径的结尾逐渐删除一个或多个部分来获得。 对于 VA 专辑的播放记录,我们可以通过将上面路径中的{artist_unique_name}换成 VA 来区分,路径如下:
/api/artists/VA/albums/{album_title}/{disc}/{track}/
除此之外我们还需要专门为存储所有专辑的数据加另一个分支:
/api/albums/
那么整个 URI 树变成了下面这样:
api
├── artists
│ ├── {'{artist}'}
│ │ └── albums
│ │ └── {'{album}'}
│ │ └── {'{disc}'}
│ │ └── {'{track}'}
│ └── VA
│ └── albums
│ └── {'{album}'}
│ └── {'{disc}'}
│ └── {'{track}'}
└── albums
对资源的操作
遵循 REST 原则,我们的 API 应该提供针对资源的 HTTP 方法。我们在此重申每个 HTTP 方法该如何使用:
- GET - 返回一个资源的表达形式;不做出任何修改
- POST - 对目标集合添加一个新的示例
- PUT - 将一个目标资源用新的表达形式替换(只当目标资源存在的时候)
- DELETE - 删除目标资源
大多数资源都应该实现 GET 方法;POST 方法一般针对‘集合’资源,PUT 和 DELETE 方法一般针对于‘个体’资源实现。 在我们这个例子中有两个例外,第一:album 资源既可以作为‘集体’资源也可以作为‘个体’资源,所以这四个 HTTP 方法都可以实现; 第二:对于 all album 这个资源来说,作为一个‘集体’资源,它并不能实现 POST 方法,因为我们可以看到它的路径是/api/albums/,我们从 URI 中并不能知道这张专辑的作者是谁,即路径中缺少我们创建新专辑需要的艺术家的信息,而艺术家是作为专辑的父节点存在的,即必须要先有艺术家才能有专辑。 所以如果我们想创建一个新的子节点,这个子节点的父节点应该要在 URI 中可以被找到,而不是被放在请求中。
我们将每个资源对应的 HTTP 方法在下表列出:
| Resource | URI | GET | POST | PUT | DELETE |
|---|---|---|---|---|---|
| artist collection | /api/artists/ | X | X | - | - |
| artist item | /api/artists/{artist}/ | X | - | X | X |
| albums by artist | /api/artists/{artist}/albums/ | X | X | - | - |
| albums by VA | /api/artists/VA/albums/ | X | X | - | - |
| all albums | /api/albums/ | X | - | - | - |
| album | /api/artists/{artist}/albums/{album}/ | X | X | X | X |
| VA album | /api/artists/VA/albums/{album}/ | X | X | X | X |
| track | /api/artists/{artist}/albums/{album}/{disc}/{track}/ | X | - | X | X |
| VA track | /api/artists/VA/albums/{album}/{disc}/{track}/ | X | - | X | X |
可以看到我们遵守了 REST 原则,每个 HTTP 方法都按在预期执行。上面这张表告诉了我们很多有用的信息:它显示了可以发出的所有可能的 HTTP 请求,甚至提示了它们的含义。 例如,如果你向 track 资源提交一个 PUT 申请,它将修改 track 的数据(更具体地,它会用请求中的数据代替原数据).
练习一:添加一个播放记录
利用上面所学到的概念,你是否能写出一个 URI 来添加一个新的名为‘Happiness’的播放记录(该播放记录是专辑‘Kallocain’中第三个播放记录,该专辑的作者是‘Paatos’),在此练习中假设这个艺术家的名字是唯一的,并且请在 URI 中将艺术家的名字全部小写。
答案:
/api/artists/paatos/albums/Kallocain/解释:我们第一步需要确定的是这个操作需要用哪一种 HTTP 方法,由于我们想要给某一张专辑加播放记录,那我们需要用到的方法是 POST,所以根据上面资源表中的信息,能用 POST 方法的资源只有五个(一般只有‘集合’资源才能使用 POST 方法):artist collection, albums by artist, albums by VA, album 和 VA album. 如果我们想给一张只有一个艺术家的专辑加播放记录,很明显我们需要操作的资源是 album
/api/artists/{artist}/albums/{album}/. 那么我们可能会好奇播放记录的信息track:Happiness; disc:3该如何加进去呢?注意,我们不能将播放记录的信息放在 URI 中,而是应该将播放记录的信息放进 POST 方法的请求中(request body):在这里把所有信息都写在 URI 中提交给 track 资源是不正确的(
/api/artists/paatos/albums/Kallocain/3/Happiness/),因为 track 作为一个‘个体’资源,并不支持 POST 方法,我们只能给一个‘集合’中添加新元素,而不能给一个‘个体’添加新记录。而/api/artists/paatos/albums/Kallocain/3/Happiness/这个 URI 支持的操作是 GET,PUT,DELETE,即当我们想要获取,修改或删除某一个确切的 track 数据时可以调用该 URI。
进入超媒体世界
为了让前端开发者了解到底前端需要传入什么数据以及所期待的返回值,我们需要将 API 详细记载。 在本课程中,我们将在 API 给出的响应中运用超媒体,在本章的例子中,我们选择用Mason作为我们的超媒体格式,因为对于定义超媒体元素并将它们连接到数据中,Mason 有着非常清晰的语法。
数据表达形式
我们的 API 是通过 JSON 交流的,对数据表达来说,这是一个很简单的序列化过程。如果客户端给/api/artists/scandal/发出了一个 GET 请求,返回的数据将会被序列化,如下:
{
"name": "Scandal",
"unique_name": "scandal",
"location": "Osaka, JP",
"formed": "2006-08-21",
"disbanded": null
}
如果客户想要添加一个新的艺术家,他们需要发送一个几乎相同的 JSON 数据(除去 unique_name,因为这个是 API 服务器自动生成的)。 这个数据的序列化过程几乎可以运用到所有模块上。
对于‘集体’资源来说,在它们的数据体中会包含一个‘items’的属性--‘items’是一个包含了这个集体资源中一部分数据或全部数据的列表。 例如 albums 资源中不仅包含描述自身信息的根级数据,还包括一个存储了 track 信息的列表。 值得注意的是,‘items’中并不用将相应的资源数据全部包含进去,只需要包含必要的信息,例如对于 album collections 来说,在‘items’中包含的数据只需要有专辑标题和艺术家名字就足够了:
{
"items": [
{
"artist": "Scandal",
"title": "Hello World"
},
]
}
如果客户想要得到‘items’中某个个体的更多详细信息,可以直接通过 URI 访问 album 个体资源来获取。
超媒体控件(Hypermedia Controls)
你可以将 API 想象成一张地图,而每一个资源就是地图中一个点,一个你最近发送了 GET 请求的资源就像是一个在说‘你在这里’的点。而‘超媒体控件’能描述逻辑上的下一步操作:下一步你将走到哪里,或者是你在的这个点下一步可以做什么。 ‘超媒体控件’与资源一起形成了一个能解释说明该如何在 API 中‘航行’的客户端状态图(state diagram).在我们刚刚学到的数据表达中,‘超媒体控件’是作为一个额外属性存在于其中的。
超媒体控件是至少两件事情的组合:链接关系("rel")和目标 URI("href").这说明了两个问题:这个控件做了什么,以及在哪里可以激活这个动作。请注意,链接关系是机器可读的关键字,而不是面向人类的描述。 许多我们常用的链接关系正在标准化,可参考(完整列表),但是 API 也可以在需要的时候给出自己的定义 - 只要每个链接关系是一直表达同一种意思即可。 当客户想要做某事时,他将使用可用的链接关系来找到这个请求应该用到的 URI。这意味着使用我们 API 的客户端永远不需要知道硬编码的 URIs - 他们将通过搜索正确的链接关系来找到 URI。
Mason 还为超媒体控件定义了一些额外的属性。其中“method”是我们将会经常使用的属性,因为它告诉应该使用哪个 HTTP 方法来发出请求(由于默认方法是 GET,所以通常 GET 方法会被省略)。 还有“title”可帮助客户(人类用户)弄清楚控件的作用。除此之外,我们还可以定义一个JSON 架构来规定发送到 API 的数据表达格式。
在 Mason 中,可以通过添加"@controls"属性将超媒体控件附加给任何对象。"@controls"本身就是一个对象,其中的属性是‘链接关系’,其值是至少具有一个属性(href)的对象。例如,这是一个带有多媒体控件的 track 个体资源,用于返回其所在的专辑的链接关系为(“向上”),编辑其信息的链接关系为(“编辑”):
{
"title": "Wings of Lead Over Dormant Seas",
"disc_number": 2,
"track_number": 1,
"length": "01:00:00",
"@controls": {
"up": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/"
},
"edit": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/2/1/",
"method": "PUT"
}
}
}
或者,如果我们希望集合中的每个个例上都有自己的 URI 可供客户端使用:
{
"items": [
{
"artist": "Scandal",
"title": "Hello World",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Hello World/"
}
}
},
{
"artist": "Scandal",
"title": "Yellow",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Yellow/"
}
}
}
]
}
自定义链接关系
在定义我们的链接关系的时候,虽然尽可能使用标准是好的,但实际上每个 API 都有许多控件,其含义无法用任何标准化关系明确表达。因此,Mason 文档可以使用链接关系命名空间来扩展可用的链接关系。Mason 命名空间定义了前缀及其关联的命名空间(类似于 XML 命名空间,请参阅CURIE)。该前缀将被添加到IANA 列表中未定义的链接关系上。 当一个链接关系以命名空间前缀为前缀时,它应被解释为在命名空间的末尾附加了关系并使关系唯一 - 即使另一个 API 定义了具有相同名称的关系,它也会有不同的命名空间前缀。例如,如果想要一个名为“albums-va”的关系来标明一个指向所有 VA 专辑集合的控件,则其完整标识符可以是http://wherever.this.server.is/musicmeta/link-relations#albums-by, 我们可以定义一个名为“mumeta”的命名空间前缀,然后这个控件看上去将会是这样:
{
"@namespaces": {
"mumeta": {
"name": "http://wherever.this.server.is/musicmeta/link-relations#"
}
},
"@controls": {
"mumeta:albums-va": {
"href": "/api/artists/VA/albums"
}
}
}
此外,如果客户端开发人员访问完整的 URL,他们应该找到有关链接关系的描述。另请注意,通常这是一个完整的 URL,因为服务器部分保证了唯一性。在后面的示例中,你将看到我们正在使用相对 URI - 这样即使服务器在不同的地址(最有可能的是 localhost:someport)中运行,指向关系描述的链接也会起作用。
有关链接关系的信息必须存储在某处。请注意,这适用于客户端开发人员,即人类。在我们的例子中,一个简单的 HTML 文档应该足以支持每个关系。这就是我们的命名空间名称以#结尾的原因。它可以方便地找到每个关系的描述。在继续之前,这里是我们的 API 使用的自定义链接关系的完整列表: add-album, add-artist, add-track, albums-all, albums-by, albums-va, artists-all, delete。
API 地图
设计 API 的最后一项业务是创建一个包含所有资源和超媒体控件的完整地图。在这个状态图中,资源是状态,超媒体控件是转换。一般来说,只有 GET 方法适用于从一种状态移动到另一种状态,因为其他方法不会返回资源表达。我们已经提出了其他方法作为箭头回到相同的状态。这是完整地图: 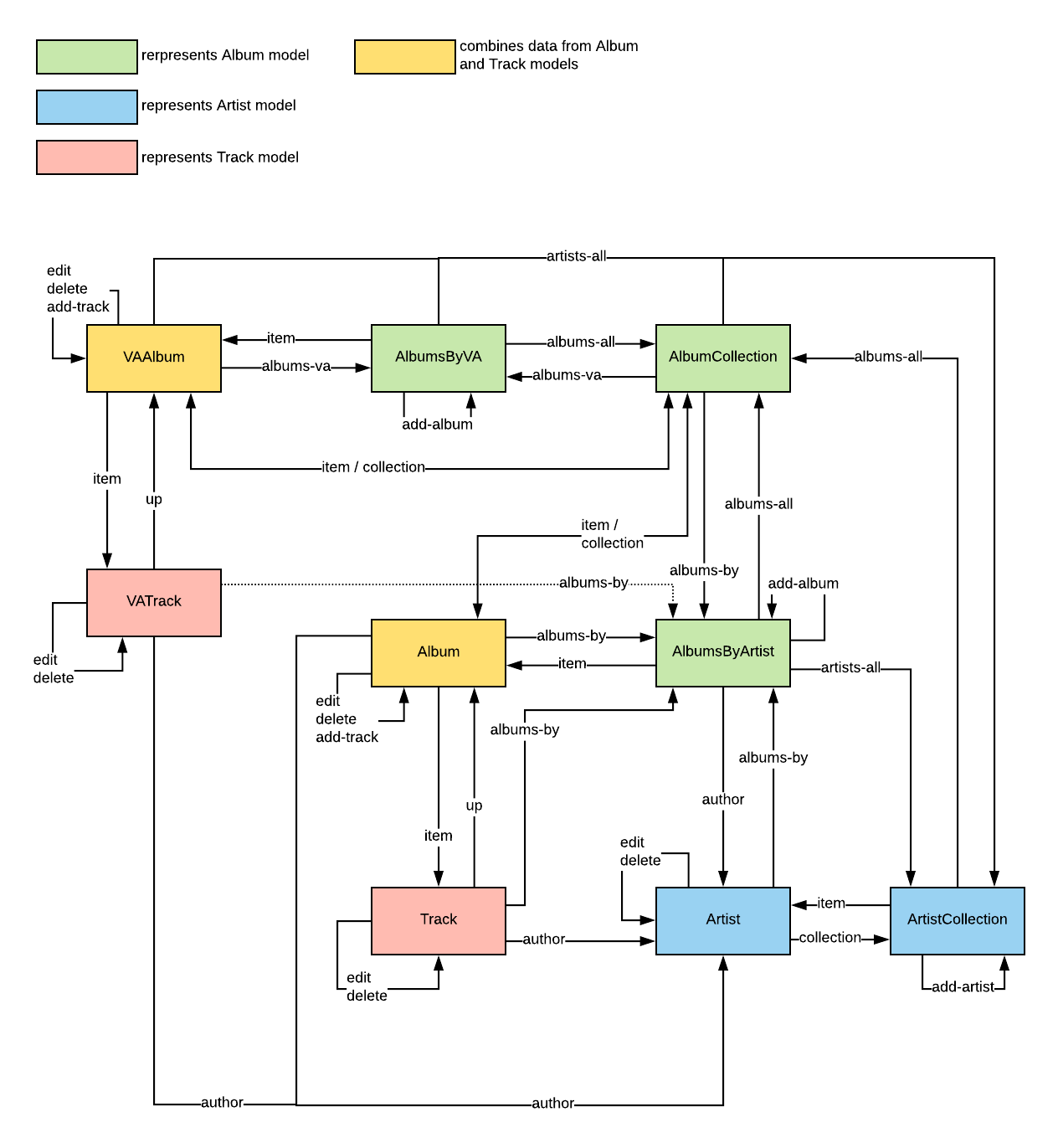
注意 1:地图中每个盒子颜色的代码仅用于教育目的,以显示数据库中的数据是如何连接到资源 - 你不需要在现实生活或自己的项目中实现这样的细节。
注意 2:地图中的链接关系“item”并不存在,实际上,这应该是“self”。在此图中,“item”用于表示这是通过个体数据的“self”链接从集合转换到个体。
这样的映射图在设计 API 时很有用,而且都应该在设计 API 返回每个单独的资源表达之前完成。由于所有操作都在这个地图中可见,因此更容易查看是否缺少某些内容。在制作图表时请记住,必须要有从一个状态到另一个状态的联通路径(连通原理)。在我们的例子中,我们在 URI 树中有三个独立的分支,因此我们必须确保每个分支之间的转换(例如,AlbumCollection 资源具有“artists-all”和“albums-va”)。
练习二:The Road to Transcendence
参考上面的状态图。我们假设你是一个机器客户端。你当前正站在 ArtistCollection 节点上,你的目标是要查找和修改有关一个有群星艺术家的专辑“Transcendental”(Mono 和 The Ocean 的合作)的数据。为了做到这一点,必须遵循哪些链接?这条路径有意义吗?请给出最短的链接关系列表(使用与上面状态图中相同的名称),从而将你从 ArtistCollection 导出到修改 VA 专辑的数据(edit)。
答案:
albums-all,albums-va,item,edit注意,最后我们是需要修改 VA 专辑中的数据,所以到达了 VAAlbum 我们还需要通过访问‘edit’链接关系来修改数据。
API 入口
关于 API 映射图的最后一点概念是入口点(Entry Point)。这应该是 API 的根源(在我们的例子中应该是:/api/,它有点像 API 的索引页面。它不是资源,通常不返回(所以它不在状态图中)。它只是显示了客户在“进入”API 时的合理启动选项。在我们的例子中,它应该包含多媒体控件来调用 GET 方法来获取艺术家集合或专辑集合(也有可能是 VA 专辑集合)。
练习三:“进入迷宫”
创建一个 MusicMeta API 入口点的 JSON 文档。它应该包含两个超媒体控件:链接到艺术家集合(Artist Collection),并链接到专辑集合(Album Collection)。你应该能够从上面的状态图中找出这些控件的链接关系。不要忘记使用 mumeta 命名空间!
带架构的高级控件
到目前为止,我们已经使用超媒体定义了可能的操作。每个操作都带有一个具有明确含义的链接关系,相关资源的地址以及要使用的 HTTP 方法。这些信息对于 GET 和 DELETE 请求是足够的,但对于 POST 和 PUT 来说还不够 - 因为我们仍然不知道应该在请求体中放什么。Mason 支持将JSON 架构添加到超媒体控件中。该架构定义了 API 将认为哪种 JSON 文档是有效的。例如,这是专辑资源的完整架构:
{
"type": "object",
"properties": {
"title": {
"description": "Album title",
"type": "string"
},
"release": {
"description": "Release date",
"type": "string",
"pattern": "^[0-9]{4}-[01][0-9]-[0-3][0-9]$"
},
"genre": {
"description": "Album's genre(s)",
"type": "string"
},
"discs": {
"description": "Number of discs",
"type": "integer",
"default": 1
}
},
"required": ["title", "release"]
}
对于上面这个对象,架构本身由三个属性组成:
- “type” - 这定义了资源数据类型,通常是“对象”但有时是“数组”
- “properties” - 一个定义了所有可能/预期属性的对象
- “required” - 一个列出必需属性的数组
“properties”中的值通常具有“描述”(“description”)(面向人类读者)和“类型”(“type”)。它们还可以具有一些其他属性,如示例中所示:pattern - 一种正则表达式,定义哪种值对此属性有效(仅与字符串兼容); default,该属性在缺失时所使用的值。这些只是 JSON 架构可以做的一些基本事情。你可以从其详述中阅读更多内容。
像这样的 JSON 架构对象可以通过被添加到 Mason 超媒体控件的“schema”属性中来发挥作用。如果你的架构特别大或者你有其他理由不将其包含在响应正文中,你可以选择从 API 服务器上的 URL(例如/ schema / album /)提供架构,并将 URL 分配给“schemaUrl”属性,以便客户端可以检索它。这样客户端就可以在将数据发送到 API 时使用架构形成正确的请求。机器客户端是否能够确定每个属性的该放的内容是一个不同的事,一种选择是使用符合标准的名称,例如我们可以使用与 MP3 文件中的 IDv2 标签相同的属性名称。
架构对于(部分)生成的具有人类用户的客户端特别有用。根据架构编写一段生成表单的代码非常简单,以便人类用户可以填充它。我们将在课程的最后一次练习中展示这一点。在 API 方面,架构实际上有双重任务 - 它还可用于验证客户端的请求(和使用该功能一样)。值得注意的是,我们示例中的日期架构并非万无一失(它会接受 2000-19-39 之类不正确的数据),在实现中必须注意到这一点。一个完全万无一失的正则表达式会很长 - 你可以看看自己能不能想出一个合适的正则表达式。
架构也可被用于使用了查询参数的资源。在这种情况下,他们描述了可接受的参数和值。 作为示例,我们可以添加一个影响专辑集合排序方式的查询参数。下面是一个添加了架构的“mumeta:albums-all”控件例子。另请注意“isHrefTemplate”的添加。
{
"@controls": {
"mumeta:albums-all": {
"href": "/api/albums/?{sortby}",
"title": "All albums",
"isHrefTemplate": true,
"schema": {
"type": "object",
"properties": {
"sortby": {
"description": "Field to use for sorting",
"type": "string",
"default": "title",
"enum": ["artist", "title", "genre", "release"]
}
},
"required": []
}
}
}
}
客户端示例
为了让你了解我们为什么要经历所有上面那些麻烦并为我们的有效负载添加一堆字节,让我们从客户的角度考虑一个小例子。假设我们的客户端是一个提交机器人(bot),可以浏览其本地音乐集合,并可以将尚不存在的艺术家/专辑元数据发送 API。 假设它的本地集合按艺术家和专辑分组。并且假设它正在检查一个包含一个专辑文件夹(“All Around Us”)的艺术家文件夹(“Miaou”)。 目标是看这个艺术家是否在该集合中,以及它是否有这个专辑。
- bot 进入 api 并通过寻找名为“mumeta:artists-all”的超媒体控件找到艺术家集合
- bot 使用超媒体控件的 href 属性向艺术家集合发送 GET
- bot 寻找一位名叫“Miaou”的艺术家,却找不到它
- 机器人寻找“mumeta:add-artist”超媒体控制
- bot 使用“mumeta:add-artist”控件的 href 属性和关联的 JSON 模式编译发送 POST 请求
- 在发送 POST 请求后,bot 从响应中的“location header”中获取新加的艺术家的地址(URI)
- bot 发送 GET 给它收到的地址
- 从艺术家出发,bot 将寻找“mumeta:albums-by”超媒体控制
- bot 发送 GET 到该控件的 href 属性,接收一个空的专辑集合
- 由于专辑不存在,bot 寻找“mumeta:add-album”超媒体控件
- bot 使用控件的 href 属性和关联的 JSON 模式编译发送 POST 请求
这个例子的重要的部分是机器人现在除了/api/之外不需要任何 URI。对于其他的资源的 URI,都可以通过寻找链接关系来获取。它访问的所有地址都是从它获得的响应中解析出来的。这些地址可能是完全随意的,但机器人仍然可以工作。 根据机器人的 AI,它可以在相当剧烈的 API 变化中存活下来(例如,当它获取艺术家表示并找到一堆控件时,它是如何被编程为遵循“mumeta:albums-by”?)
关于超媒体 APIs 的一个非常酷的事情是它们通常拥有一个通用客户端来浏览任何有效的 API。客户端将使用超媒体控件生成适用于人类的网站,以提供从一个视图到另一个视图的链接,以及用于生成表单的架构。
超媒体档案(Hypermedia Profiles)
通过添加超媒体,我们已经创建了一个机器客户端可以在其中“航行”的 API,因为它已经能了解每个链接关系的含义以及资源表达中每个属性的含义。但机器究竟是如何学习这些东西的呢?这是 API 开发的持续挑战 - 现在一种方法是让人类开发人员学习资源档案。档案文件会用人类可读的格式描述资源的语义。这样人类开发人员可以将这些知识传递给他们的客户端,或者客户的人类用户可以在使用 API 时使用这些知识。
什么是档案文件?
关于档案文件究竟应该是什么,或者如何编写配置文件,没有普遍的共识。但是无论如何编写,档案中都应该具有(资源表达中)属性的语义描述符和可以采取的操作的协议语义(或与资源相关联的链接关系列表)。集合不一定有自己的文档,例如本章练习中的例子。除了专辑资源,因为它既可以是一个集合,也可以是一个个体。
如果你的资源中有相对常见的内容表达,建议使用标准(或标准提案)中定义的属性。如果你的整个资源表示符合标准就更好。你可以在https://schema.org/中查找标准表达。我们的示例 API 的一个重要的未来步骤是使用此架构中的属性作为专辑和播放记录的属性。
分布式档案
与链接关系一样,关于你的档案文件的信息应该可以从某个位置访问。在我们的示例中,我们选择使用一个路径/profiles/{profile_name}/将它们作为 HTML 页面从服务器分发。同时可以使用“profile”链接关系将档案文件的链接作为超媒体控件插入数据表达中。例如,要从 track 表达中获取 track 档案文件:
{
"@controls": {
"profile": {
"href": "/profiles/track/"
}
}
}
另一种方式是在回应中使用 HTTP Link header:
Link: <http://where.ever.the.server.is/profiles/track/>; rel="profile"
然而,这有点模棱两可。我们的专辑资源是一个应该链接到两个档案文件的示例 - 专辑和播放记录。出于这个原因,我们将档案文件作为超媒体控件包含在数据表达内,对于集合类型的资源,我们在每个个体资源中都包含了一个档案控件。
API 文档
为了使我们最终的 API 和它的文档一样完美,应参考一种流行的标准记录 API,例如API Blueprint或OpenAPI。这两个标准都带有一套很好的相关工具:从文档浏览到自动化测试生成(更多示例请参见API Blueprint 工具部分)。在本练习中,我们选择使用 API Blueprint,并使用Apiary 编辑器来创建交互式文档。
API Blueprint 的语法相对简单。你可以先阅读官方教程,你还可以从我们的示例中学习其余部分。你应该创建一个 Apiary 帐户并使用其中的编辑器来完成剩余的示例和任务。
描述一个资源
这是一个非常简短的指南,说明如何在文档中表示每个资源。资源描述以其名称开头,后面跟着的方括号中的包含了它的 URI,除此之外你可以在这一行下面加上面向人类的描述性语言,例如:
## Album Collection [/api/albums/]
This is a collection of all the albums
如果资源的 URI 中包含变量,则应将这些变量描述为参数,如下所示:
## Albums by Artist [/api/albums/{artist}/]
+ Parameters
+ artist (string) - artist's unique name (unique_name)
在此之后,每个操作都需要被描述,包括一个描述性标题和 HTTP 方法,同样你可以在下方加上面向人类的描述。
### List all albums [GET]
对于每个操作,其中应该包含其链接关系。还需要包含请求部分和响应部分(每个可能的状态代码)。所有这些部分还应包含有效请求和 API 响应的示例。 例如,Artist 的 GET 方法的专辑文档(为简洁起见省略了消息体,稍后参见完整示例)。
### List albums by artist [GET]
+ Relation: albums-by
+ Request
+ Headers
Accept: application/vnd.mason+json
+ Response 200 (application/vnd.mason+json)
+ Body
...
+ Response 404 (application/vnd.mason+json)
+ Body
...
超媒体问题
使用这些非常好的标准时我们有一个不便之处:它们不支持超媒体。也就是说,该语法没有任何方式能将链接关系或资源档案文件包含到同一文档中。这就是我们实际上只是将服务器作为 HTML 文件提供服务的原因。但是对于我们的 API 蓝图示例,以及最后的任务,我们实际上会做一些过度使用。 具体地说,我们将包括两个组:链接关系和档案文件,在这些组内部,每个链接关系和档案文件都将按照资源的语法添加。
这样做可以创建更好的浏览文档,因为所有内容都会整齐地显示在索引中,我们可以在文档中放置锚链接以便快速访问不同的部分。但是,这种故意滥用与自动化工具不能很好地兼容,因为自动化工具试图将所有内容视为资源。 现有的提议是将超媒体正确地包含在语法中,但是就目前为止,我们只有这两个选项:要么我们不在 Apiary 文档中包含链接关系和资源档案文件信息,要么将它们作为“资源”放入。
API Blueprint 示例
以下是记录 API 中专辑相关资源的示例。由于文本文件本身过长,我们建议你将内容复制到新的 Apiary 项目中。
重要提示:该编辑器似乎没有自动保存功能。确保在每次更改后交替按下“保存”按钮 - 首先确保文档不存在语法警告。 除了主体元素外,所有内容都应缩进 1 个制表符或 4 个空格 - 这些空格元素应相对于节标题缩进两次 + Body.
你还可以转到“文档”选项卡,使用整个屏幕宽度浏览 API 文档。你可以单击文档中的各种请求在文档浏览器的右侧查看请求的详细信息(以及可能的响应)。
练习四:API Blueprint - Artist
为了完成本练习并学习 API Blueprint,我们希望你完成 Music Meta API 文档的一部分。我们提供的示例包含专辑的资源组。你的工作是为艺术家添加资源组。
学习目标:了解如何编写有效的 API Blueprint。了解如何正确记录资源。
如何开始:你应该在我们给出的示例中添加你自己的部分。如果你尚未下载我们提供的示例并将其放入 Apiary,请立即执行此操作。添加艺术家的资源组,并开始对两个新资源的描述。 你还应该保留前面的状态图,以及我们在开始时显示的数据库模型。提示:按照示例进行操作。你的资源描述必须包含所有相同的信息。你可以为数据提供自己的艺术家示例。
艺术家集合资源(Artist Collection) 艺术家集合包括所有艺术家。对于每个艺术家,除 ID 之外的所有列值都显示在其集合条目中,使用与数据库列相同的名称。该资源支持两种方法:GET 用于检索描述,POST 用于创建新的艺术家。
对于 GET,必须包含一个示例响应主体,其中包含从状态图中的 ArtistCollection 资源引出的所有控件。请注意,某些控件位于艺术家条目中,而不是在根级别,并且不要忘记使用名称空间。另请注意,add-artist 需要包含 JSON 模式。响应机构还应包括至少一位艺术家的数据。艺术家条目应该是“items”属性中的数组,并且第一个艺术家必须是你知道存在的一个(即一个来自其他示例,或者你的 POST 示例请求中的一个)。
对于 POST,必须包含一个有效的示例请求正文,其中包含所有字段的值。同时还必须包含以下错误代码的响应:400 和 415.你不需要包含响应正文。艺术家资源(Artist Item) 艺术家资源包括与艺术家集合资源中的一个艺术家相同的信息。该资源支持三种方法:GET,PUT 和 DELETE。资源应描述你知道存在的艺术家。 对于 GET,必须包含一个示例响应主体,其中包含从状态图中 Artist 资源引出的所有控件。编辑链接(edit)还必须包含 JSON 模式。除了 200 响应,还添加 404(不需要响应正文)。 对于 PUT,必须包含具有所有字段值的有效示例请求正文。还必须包含以下错误代码的响应:400,404,415。 对于 DELETE,你只需要使用正确的状态代码进行回复,唯一的错误码是 404。